What is so unique about Unison?

Software engineer at the intersection of functional programming, product development and open-source
I have recently started exploring the Unison programming language. Some programming languages are good because they improve the current state of affairs. For example Gleam brings type-safety to the Erlang platform. Other languages are game-changers:
When Scala was introduced, it brought an incredible amount of (statically-typed) functional programming features to the JVM. This changed the way we approached mutability, error management, concurrency, and structured our programs.
Verse unifies functional-programming and logical programming, where notions of failure, multiple-valued variables, and transactions, are baked into the language. This changes the way we think about control flow.
Unison is a frictionless language. It builds on the idea of "immutable code" to give us a huge productivity boost for writing cloud applications.
In this post, I am sharing my first steps with Unison. The parts where I was delighted but also the parts where I was confused. I will only talk about my experience of developing a small library for now. Part 2 will be about developing a full cloud application for my own needs.
First steps
I didn't need much to get started with Unison:
An executable called the
Unison Code Manager(ucmfor short). It is available as a nix package, so it was very easy for me to install it withflox.VS Code with the Unison plugin.
I then created a quickstart project with project.create quickstart using ucm. With this project, I was all setup for coding. Here is a simple hello function:
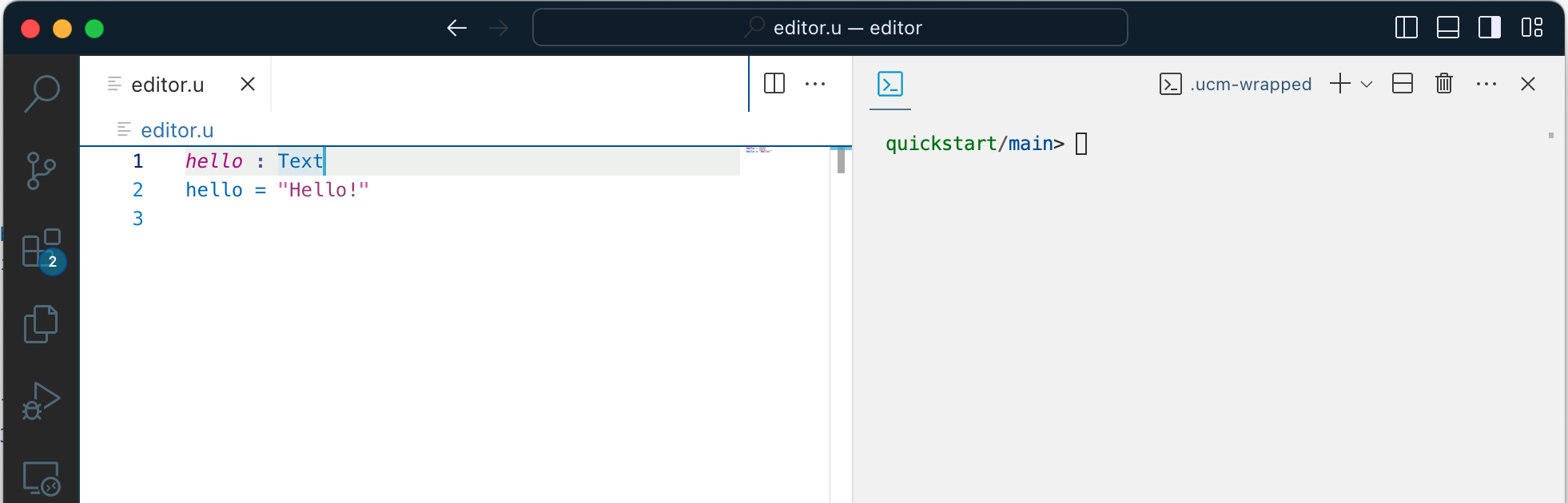
The first unusual thing with unison is that files don't matter. A convenient setup for your editor is a split screen as above with just one file on the left, and ucm on the right. Where is my code then? It is in a database:
ll $HOME/.unison/v2
Permissions Size User Date Modified Name
.rw-r--r--@ 0 etorreborre 14 Apr 12:48 unison.lockfile
.rw-r--r--@ 13M etorreborre 14 Apr 12:55 unison.sqlite3
Then, I went through the Unison language tour and learned how to:
Search for functions: by name, but also by type!
Create new functions and add them to my codebase.
Test my code by either running it or writing tests.
Not impressed? Let's have a closer look!
Search by type
Haskell users know the benefits of a tool like Hoogle. With such a tool, you can search functions by type. This is soooooo convenient! "How do I serialize Text to Bytes?". Just type find : Text -> Bytes and ucm returns all the functions with that signature:
1. lib.base.Text.toUtf8 : Text -> Bytes
2. lib.base.IO.net.URI.Path.encode.segment : Text -> Bytes
This even works when there are type parameters (Hoogle is better though because it will also show you functions where the order of parameters is slightly different).
Add a function to the project
Once a function typechecks, you can add it to your project, or update it, if was added before. This has profound implications:
All the code added to your project always compiles. If an updated definition conflicts with the previous version, then all the conflicting code is brought up to be fixed.
Adding a function to your project is also the equivalent of committing it. No more
git add .; git commit -m "add some code". Later on, sharing the code with others is just a matter of runningpush.Codebase changes can be reversed by using the
reflog, as you would do with git.The project knows about functions, not just text. This means that:
You can easily rename a function.
You can give several aliases to the same function. Internally, a function is identified by the hash of its contents.
You can create patches that are selectively applied to part of the code, so that the result still typechecks (I haven't played too much with that though).
Run and test my code
Veteran LISP programmers know the value of having a REPL at their fingertips. With Unison, it is as simple as writing a "watch expression", with >:
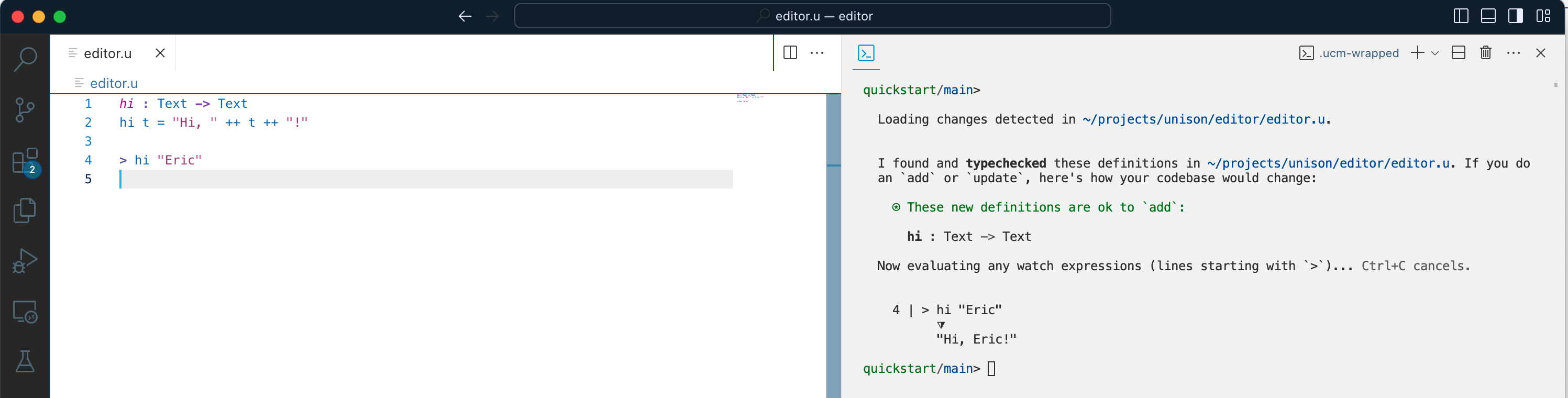
That expression is automatically evaluated in ucm so you get immediate feedback on your code. Writing a test is no different, except that you give it a name, and use the test library functions:
test> hi.test = verify do
ensureEqual (hi "Eric") "Hi, Eric!"
This test is just another term that can be added to the code base to grow the test suite. If it passes of course! Two things to note:
When you change code in your editor, all the tests are re-executed. If those tests don't depend on some changed code, their result is cached, they are not re-executed!
This also means that you can break previously added tests, which are present in your editor anymore, when updating a function. In that case, you can call
testinucmto re-run all the tests.
Some feedback from my first steps
I don't want to give the impression that everything is perfect. The language tour and first experience could be improved:
In
ucm,typingfn + ←does not go to the beginning of the line as it does in myzshterminal.Hovering over a term shows its definition. It would be great to also be able to:
Show the doc.
Show the code.
Open the term in the editor to modify it.
This would reduce the amount of back and forth switching between the editor and
ucm.Selecting a term to edit it is a bit crude. The term to edit is added at the top of the current file and the rest of the file is commented out. In many cases, I want my existing code to stay in scope.
Some crucial aspects of the platform are still being polished! While I was going on the language tour, the Unison team realized that the functions used to do property-based testing were not so great and revamped the whole thing. This means that some of the documentation or blog post you read about Unison might not always reflect the latest and greatest.
Similarly, the concept of namespacing for terms (the
name1.name2.termnotation) is a bit in flux. There are still a number of issues regarding the interactions ofucmcommands for navigating/updating the code:cd,up,ls,move,... and the qualifiers that need to be written or not in the edited code.The VS Code integration with
ucmcould be improved. Some specific windows would be nice to display:All the compilation errors (and being able to jump to one of them)
All the tests (in the current file, in the whole project)
All the watch expressions (in the current file, in the whole project)
I think I had a few bugs with the editor:
Sometimes
ucmis happy with a function, yet the editor shows an error message.If you define a
==function, with its documentation, add it, and try to edit the documentation again, then the editor shows an "offset" error for(Name.==.doc).
Since we pay less attention to files, it's easy to delete terms that were not yet added, i.e. losing that code! In that case having an editor with a good local history is important.
My first library
I want to use Unison to develop a cloud application but I think that it is important to get comfortable first with a new programming language and the full lifecycle of: coding, testing, releasing. So I decided to implement a library that did not exist yet: @etorreborre/multimap.
This library provides a data type, a MultiMap. This is simply a wrapper for a Map k vs where vs is a list of values. MultiMaps can be useful in a variety of contexts. For example, in Unison we could have a MultiMap tracking all the existing names for a given term hash.
That led me to appreciate a few more cool things about Unison.
Documentation is first class
Yes, in Unison, the documentation for a term is itself a term. It has a name, a namespace, can be added and edited. It can also be executed! This means that you can put both Markdown text in a block of documentation and some valid Unison code:
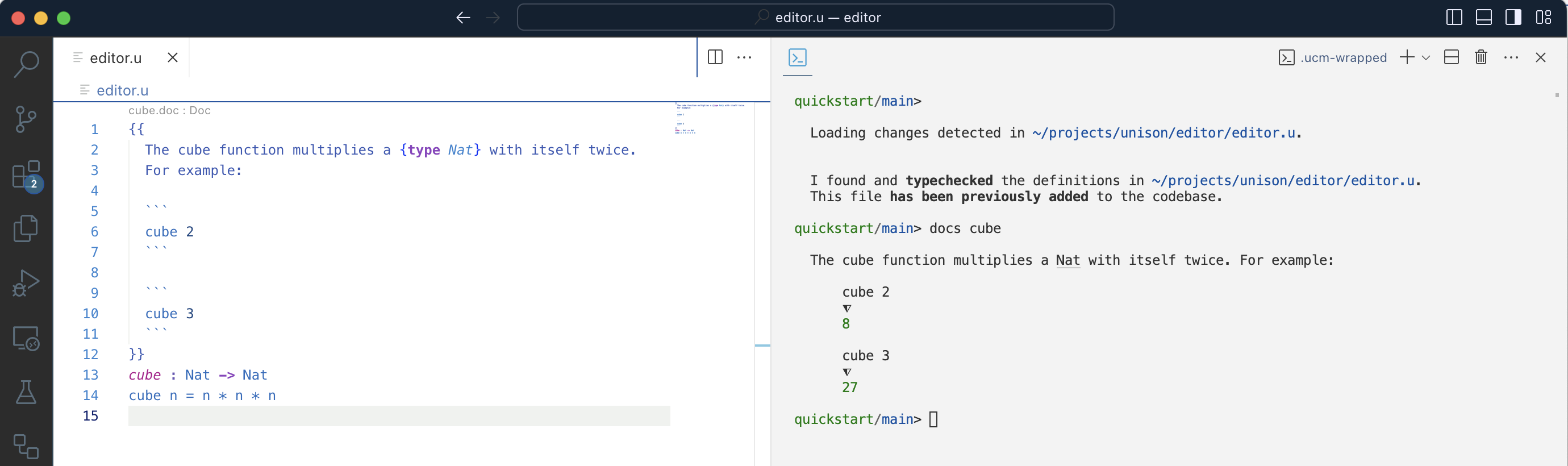
Then, the docs command executes and displays the result on the right. And eventually that documentation is published as some beautiful HTML:

Why is this important? This matters a lot because now we have a much greater incentive to write great docs:
They always typecheck.
They are refactored like the rest of the code when a name is updated.
Links to other terms are always working.
You can provide great examples inline.
Less attention to files = more focus
When writing Unison code we don't jump from file to file. We keep editing code in the same window. This means that it's perfectly ok to clear everything and just focus on one or two functions at the time, with the corresponding tests. This is strangely liberating.
Less attention to files = more normalization
Many people came to the idea that a good syntax formatter was the best way to put formatting discussions to rest. For example, Go came up with a default formatter from the start, and in Haskell, a "no-configuration" formatter like ormolu, won the hearts of many teams.
Unison goes one step further since no text is really stored, only an AST. This means that you don't really care if you prefix all your functions with their namespace, or add a bunch of use clause at the beginning of the file. Eventually the code will be stored and rendered in the same way. For example:
use MultiMap empty size isEmpty
test> MultiMap.tests.ex1 = verify do
size empty === 0
isEmpty empty === true
is reformatted as:
MultiMap.tests.ex1 : [Result]
MultiMap.tests.ex1 = test.verify do
use MultiMap empty
MultiMap.size empty === 0
MultiMap.isEmpty empty === true
Todo
This is a small but useful thing when you use types to design your code. For example, you know that you will need a function with a given type but you don't want to lose focus by implementing it right away. Just leave todo as its implementation. This is always a valid term!
Testing
Testing is great! Unison comes with an effect system, called abilities, where a piece of code can interact with a handler to decide how the computation should be executed. This possibly sound nebulous, but you probably have already used something like this if you have:
Thrown exceptions. Then, a handler knows what to do with the exception. "Resumable exceptions" are even better since the handler can provide a value to continue the computation.
Used
asyncin Rust. The handler is an executor that puts the current code on hold, then resumes it when a thread is available.Used a generator in Python with
yield. In that case, the handler uses the yielded value then resumes the code, to get the next value.
The abilities used for testing in Unison are:
Randomto provide randomly generated values.Eachto repeat a piece of code, possibly with a different value, taken from a list of values.Exceptionto abort the test in case of a failure.
This means that you have a very convenient way to mix enumeration testing, where data is tested exhaustively, and random testing, where you let randomness explore the test data. You can read some examples on Paul Chiusano's blog post on the subject.
Publishing the library
Publishing a library is very easy:
Provide a README, in the form of a documentation term called,...
README.Use the
Licensedatatype to provide a license for your project (andmitas aLicenseTypefor example).pushand press theCut a new releasebutton on the project page.
Some question marks
The MultiMap library is not so small. It contains more than 200 terms and 2000 lines of code (counting the documentation. It's code, right 😊?).
With this library I could get a taste of what it meant to work with larger projects in Unison and ask myself a few questions.
Namespaces
Namespaces are mostly irrelevant for a library like MultiMap since everything is at the same level. But where do you put tests? Possibly, we want to separate the testing code from the "production" code. I opted for the MultiMap.tests namespace (Unison's base library does things a bit differently). This has the advantage of offering a clear separation, and if you want to have a look at all the tests you can edit.namespace MultiMap.tests.
There is also a bit of "convention over configuration". The lib namespace in a given project is treated specially. It contains all the project dependencies, including Unison's base library. If you want to upgrade that library or add another library as a dependency you need to pull it, inside the lib namespace:
pull @unison/json-core/releases/1.0.3 lib.jsonCore_1_0_3
As you can see, there are no real constraints for going from json-core/releases/1.0.3 to lib.jsonCore_1_0_3. I think I would have preferred a pull dependency @unison/json-core/releases/1.0.3 command doing the right thing for me.
I also made the mistake of pulling the full Unison base library directly into my top-level namespace 😰. Then I really had to learn how to remove terms and namespaces 😁.
Privacy
Closely related to namespaces is privacy. There's no notion of public/private in Unison and no notion of modules. Only namespaces. In MultiMap there are only 2 functions that are implementation functions. I decided to "hide" them in a private namespace.
I think that having the ability to truly forbid some terms to be seen outside of their packages would help when scaling Unison programs to large programs.
No typeclasses
I like to call typeclasses "interfaces for data types", and as such, I think they play an important role for modularity. They also come with all sort of questions:
How do you pass typeclass instances where needed?
How do create/resolve typeclass instances?
Unison does not have typeclasses, and I can understand why. While they are incredibly convenient, they also make a programming language a lot more complex. OCaml, or Elm, for example, are two functional programming languages with no support for typeclasses.
As a matter of convenience, Unison has universal equality and universal ordering, which are both structural. What does that mean?
This means that when you define any data type, for example Person, equality and ordering are based on what is inside the data type:
type Person = {
name: Text,
age: Nat,
}
The Universal.eq and the Universal.gt functions compare 2 Persons first based on their name, then on their age. This even works with functions! Two functions are equal if the hash of their content is equal.
Structural equality is not controversial, but structural ordering is more questionable:
We might want to define different orderings for the same data type.
I'd rather avoid breaking code if I simply swap two fields in my data type.
As a result, some Unison APIs use a comparison function parameter to specify exactly how elements must be compared. But this is not the case for some data types like Map or Set.
Large refactorings
While developing the MultiMap library, I inadvertently set myself up for a large refactoring. I initially started with MultiMap = Map k [v] and later, much later, realized that a more correct definition was MultiMap = Map k (List.Nonempty v).
Changing the datatype, and trying to add the new definition, triggered the typechecker, which was very unhappy with this change. ucm brought most of the definitions into scope and told me to fix them. This has been unfortunately a bit painful experience:
Only some errors are displayed at the time. Fixing one issue triggers another issue in a different place and you don't really know when the whole process is going to stop.
Some names were replaced with their hash.
After fixing all issues in sight, I entered
updatebutucmtold me that some code was still not compiling, commented out all the previous code, only to put another wall of text in front of me. Was it some new code, a bit of the old code that was still not compiling, some additional tests? Eventually, I had the impression of writing some fixes twice.
That made me wonder if more tooling was needed for large codebases, in order to support deep refactorings.
My first contributions
During the development of the MultiMap library, I added a few functions that were missing from the List and List.Nonempty data types. The whole process was really simple:
Create a branch in @unison/base:
branche.create /mybranch.Add some new functions + doc + tests.
push.Open a contribution in the corresponding project (much like a pull request in Github).
All of this, except the last step, is done in ucm and I can foresee a future where even the last step is supported in ucm so that you don't even have to leave your development environment to collaborate on projects.
Conclusion
Despite some of the shortcomings mentioned above, I can't wait to develop my first cloud application. This is going to be an application for importing bank data into my accounting software. My prediction is that most of the difficulty will come from the core of the application:
Dealing with authentication on both systems.
Navigating both data models.
Determining what is "new" data and what is already imported data.
I hope that, on the contrary, thanks to Unison Cloud, the technical aspects will be a breeze:
Deploying the application.
Monitoring it.
Using secrets.
Interacting with HTTP APIs.
Maybe storing a bit of data.
Stay tuned for part 2, and don't hesitate to give Unison a go, it is really a refreshing experience!




